About
- Talk on Clojure data-recur meeting
- Benchmarks
- Comparison/Advantages with other larger than memory systems
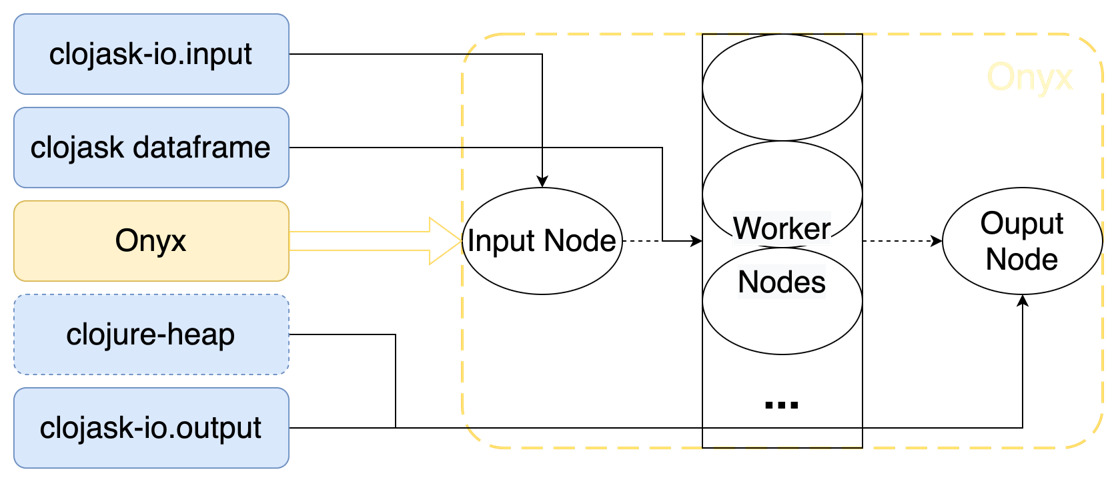
- Clojask Library Ecosystem
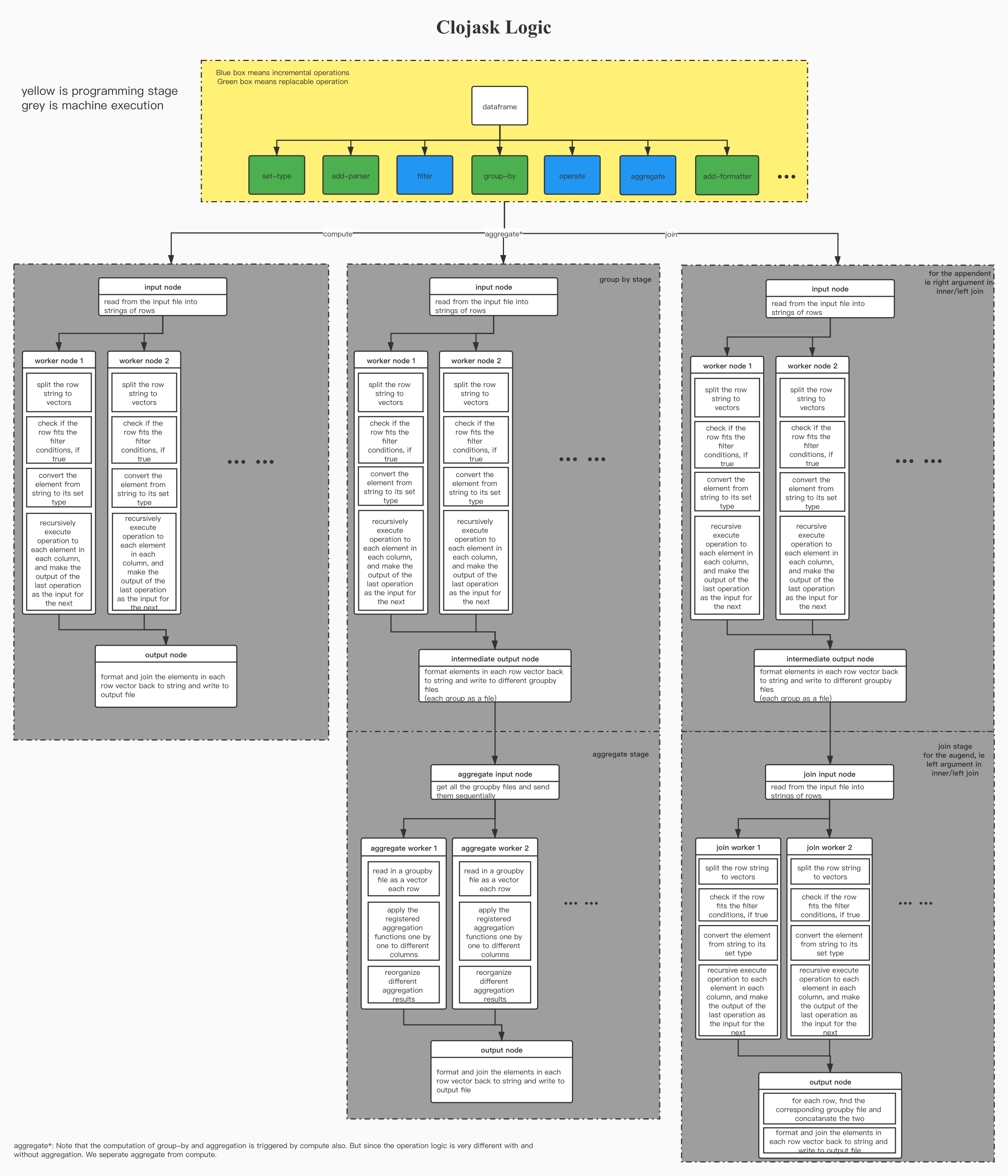
- Clojask Logic Flow Diagram
Talk on Clojure data-recur meeting
This talk is about the general information and status of the project as of Oct 2022. (From: 9:09 To: 58:02)
Benchmarks
Number of workers = 4
| Operation | Dask (N=1.8M) | Dask (N=3.6M) | Dask (N=80M)* | Clojask (N=1.8M) | Clojask (N=3.6M) | Clojask (N=80M) |
|---|---|---|---|---|---|---|
| Element-wise operation | 119.3 | 261.3 | N/A | 72.3 | 133.3 | 1836.6 |
| Row-wise selection | 115.0 | 232.0 | N/A | 67.9 | 145.6 | 1757.5 |
| Aggregation | 116.0 | 226.7 | N/A | 58.6 | 112.1 | 1236.9 |
| Groupby-aggregate | 116.7 | 229.3 | N/A | 459.4 | 803.1 | 25860.0 |
| Left join | 114.7 | 248.7 | N/A | 1174.4 | 2310.2 | 14007.9 |
| Inner join | 116.7 | 242.0 | N/A | 1138.8 | 2768.5 | 21609.3 |
| Rolling join | - | - | - | 2812.1 | 3943.1 | > 28800 |
Remarks:
- N = Number of lines in csv file
- All benchmarks are in the unit of second (s)
- All benchmarks are inclusive of the time used for importing necssary libraries, loading the dataframe from csv file and ouputting the processed dataframe to one single csv file.
- *In the case of Dask (N=80M) the program could not manage to complete the operation in 7 hours
System info
'platform': 'Darwin',
'platform-release': '20.4.0',
'platform-version': 'Darwin Kernel Version 20.4.0: Thu Apr 22 21:46:47 PDT 2021; root:xnu-7195.101.2~1/RELEASE_X86_64',
'architecture': 'x86_64',
'processor': 'i386',
'ram': '8 GB'
Source code
The benchmarking code for Dask and Clojask could be found here respectively:
Comparison/Advantages with other larger than memory systems
Hadoop MapReduce
| Functions | Clojask | Hadoop MapReduce |
|---|---|---|
| Larger-than-memory source file | ✅ | ✅ |
| Write intermediate results to tmp files | ✅ | ✅ |
| MapReduce paradigm | ✅ | ✅ |
| Join, filter, aggregate, etc. on large files | ✅ | ❌ |
Spark
| Functions | Clojask | Spark |
|---|---|---|
| Construct operations' DAG | ❌ | ✅ |
| Join, filter, aggregate, etc | ✅ | ✅ |
| Cache intermediate results between stages in memory | ❌ | ✅ |
| Minimum memory usage | ✅ | ❌ |
Clojask Library Ecosystem
(Click to view a closeup of image)
Clojask Logic Flow Diagram
(Click to view a closeup of image)